
Experimenting with AI in a Living Literature Review
From automating conference scrapes to stress-testing synthesis: a look at how AI tools like NotebookLM and OpenAI’s Agent mode support—and struggle with—the workflow of a living literature review.
The AI Accountability Review (AIAR) is a living literature review with the goal of tracking literature on the topic of AI accountability for an audience of researchers and policymakers. I write posts that either focus on translating a single piece of literature or that synthesize several pieces of literature towards policy implications. How could AI help with this process?
I recently came across a paper by Fok et al (2025) that’s been useful in helping me organize the various AI experiments I’ve been trying. Based on interviews with researchers who have written literature reviews the paper helps to understand their overall process and some of the ways they conceptualize the use of AI in that process.

The findings articulate a set of four phases to the literature review process that participants engaged in: search, appraisal, synthesis, and interpretation. The paper also identifies some of the ways AI can support updating of reviews, namely through automation and in providing a second opinion. My own use of AI for AIAR has been most useful for automating (with oversight) some of the appraisal aspects of the process, and in providing second opinions on appraisal and synthesis. I have also dabbled in some use cases that more directly do synthesis and interpretation, but these have been less successful. And I haven’t really tried any AI use cases for search, because I think that setting the search scope for the review is something that needs to be closely managed by me. Let’s walk through some of the different things I’ve tried.
Scraping, Formatting, and Promotion
Probably the most time-saving use case I’ve found is to use OpenAI’s Agent mode to help collect conference proceedings papers that I want to review. Some conferences have non-standard presentations of information, but Agent mode is pretty adept at navigating websites to collect papers and format them as RSS feeds. I plug those feeds into my triage workflow on InoReader, which streamlines the appraisal process of papers. It can help to be explicit in the prompt and identify a structured data (e.g. JSON) version of the proceedings. And while this process is mostly automated I find that I do still need to double-check the outputs to make sure it was a comprehensive scrape.
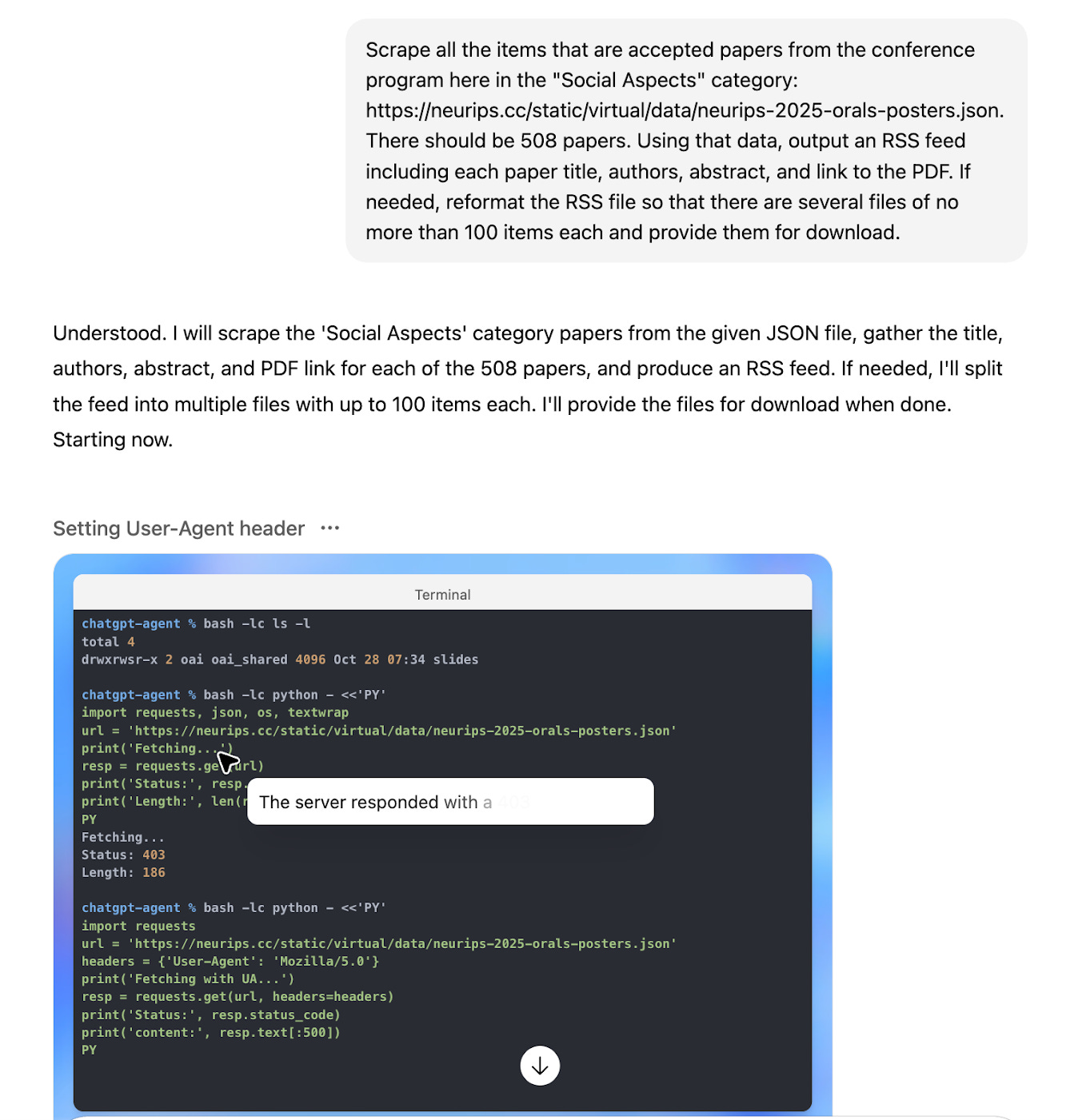
I have also experimented with using Agent mode to gather email addresses for each of the primary authors of papers cited by one of my posts, and to then draft a short personalized note notifying the person about the post. I wasn’t intrepid enough to automate the actual emailing, but I did manually copy and send some of the emails (after light editing) and even got a response from one. Promoting AIAR on social media could be a full time job, but having the AI do some of the grunt work of getting email addresses and drafting emails lowers the barrier a bit.

Article Appraisal
One of the nice built-in features of InoReader is that for any item in a feed I am tracking, I can trigger a custom prompt to an LLM. Using this feature I can get a quick second opinion from the LLM on whether the item might be relevant to my audience. Admittedly I don’t use this all that often, but I do occasionally engage it. One of the issues is that not all the RSS feeds I follow have full abstract text and so this limits the applicability. I do think there’s real potential in having AI help think through what items have implications for your intended audience, and there’s probably a lot more sophistication that could be applied in how to do this computationally beyond the integrated prompting in InoReader, such as by simulating ideal audience members and what they would want to know about an item.

Some articles on AIAR reflect the synthesis of a cluster of literature. As a living literature review the goal is to update these over time with other literature relevant to the cluster. I’ve been experimenting with LLMs to support this process. Using a Google Colab notebook I input the URL of the base article to be updated and scrape the full text. Then I prompt an LLM to evaluate a stream of literature for relevance to that article. The prompt is critical here. What I’m looking for are new papers that might directly update, change, or provide new context to any of the claims in the original article, to find new papers that might actually make a difference.
Each paper is rated for relevance, and that rating is paired with a table listing claims from the original article and ideas from the new paper that might bear on those claims. The table facilitates my appraisal of the new paper. The output looks like this:

So far this is promising, but there’s still work to do to evaluate it and set it up as an ongoing monitoring process that fully integrates with my InoReader appraisal workflow. In principle I’d set this up for each of the base articles in AIAR, and then monitor literature from something like OpenAlex to create a continuously updated feed of potentially relevant papers.
Grounded Synthesis
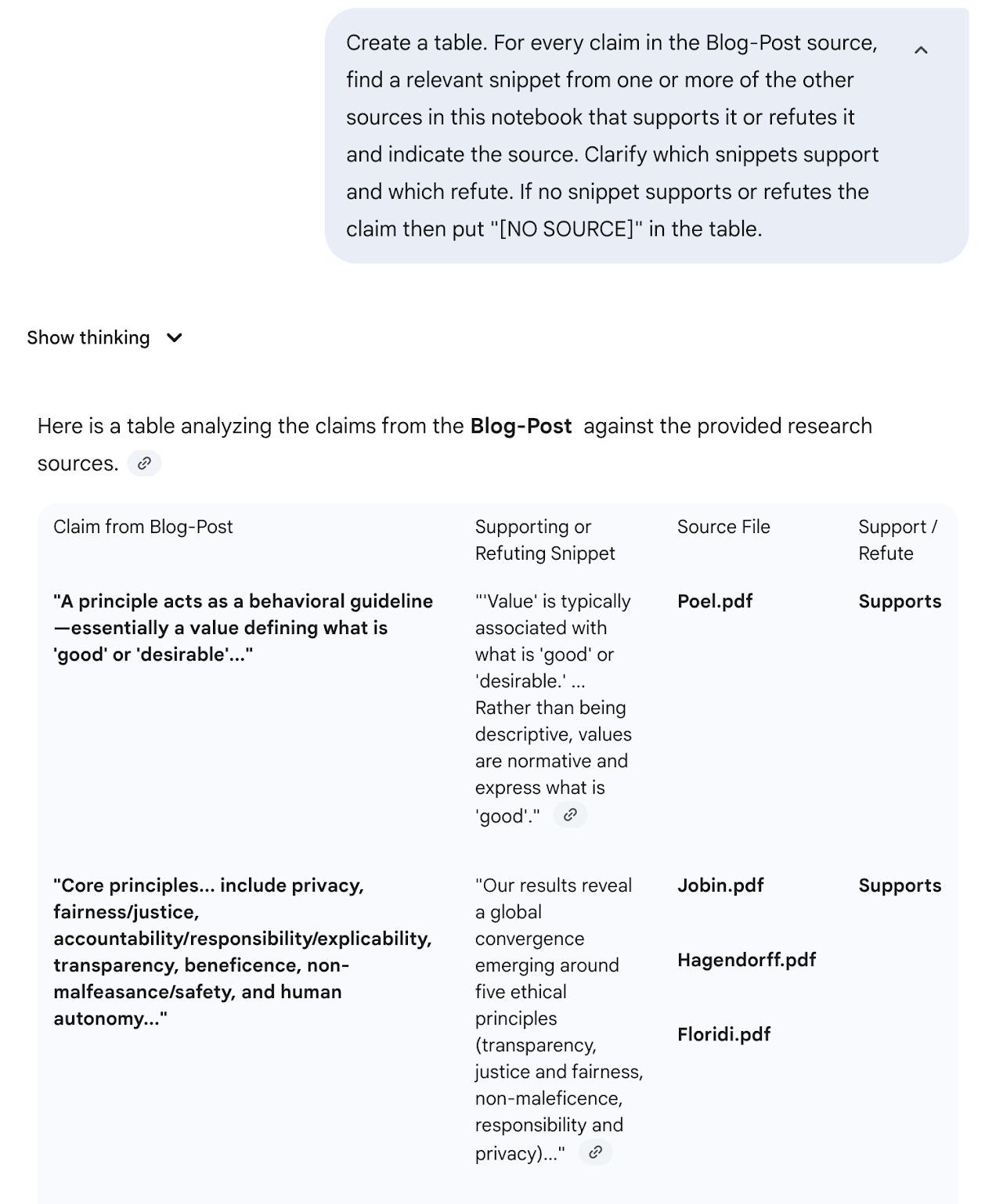
Google’s NotebookLM has turned into an increasingly powerful tool that can be used to interactively synthesize curations of articles. For my article on AI Ethics Principles and Accountability, I even published a notebook with all of the sources I had used to write the article. While the original goal with creating the notebook here was to allow readers to interactively explore the literature, I also realized that I could also use this to provide a second opinion on my own synthesis. Using Gemini, you can refer to a notebook of curated sources in NotebookLM and so I prompted it to create a table listing the supporting evidence for every claim in the post. In the absence of an editor, this can be a useful double-check to make sure you’re staying honest to the underlying literature in your synthesis. I think this kind of approach could potentially also be useful in an article update process to assess whether claims in new papers support or refute the existing claims you’ve written.
Still, I am a bit cautious about relying on LLMs, even closely grounded ones, in helping to synthesize literature for AIAR. In an early experiment, I loaded up NotebookLM with the entirety of the Fairness, Accountability, and Transparency Conference proceedings from 2025. I asked Gemini (with access to the Notebook) to look for clusters of papers that were thematically related to each other and to the topic of the blog. While some of these clusters seemed relevant and overlapped with my own perception of themes, others seemed more tenuous in the solidity of the theme and its relevance to AIAR. Synthesis is to a large degree about framing and finding a consistent thread, and I don’t think even the best LLMs are able to do this in a way that is satisfying.
As a Writing Aid
I have attempted to use LLMs (primarily Gemini, sometimes directly in NotebookLM) to help draft five of the posts for AIAR, three of which were based on translating a single paper, and two of which were based on clusters of papers.
I found that for the articles based on clusters the LLM was wholly unsuited to the task of synthesis: I ended up using none of the generated text. Even including all of the paper texts and my notes on those papers in the prompt, I was left feeling that the synthesized text didn’t capture what was interesting or important about the cluster. This again goes back to the idea of framing, structuring, and finding the aspects of relevance that I think are important within the field and to my intended audience. But this also relates to the interpretation phase and the “identification of key challenges, future trends, and open research opportunities” (Fok et al, 2025). All of this is consistent with what some editors at Science found when they tried to use ChatGPT to translate research papers.
For the three articles that were more direct translations of individual research papers I had slightly more success with incorporating AI generated text. In this post, I used almost 50% of the generated text in the final piece, which warranted a disclosure at the bottom of the post: “Some text in this post was adapted based on suggestions from AI.” I think this was somewhat successful because I prompted the model with details on the aspects of the paper I wanted the post to focus on, and that the post itself was more descriptive than synthetic or interpretive. The parts of the post that I wrote were the more interpretive aspects, putting the research into a broader context and considering its relevance to the audience. In another post (excepted below), I was also able to use some chunks of descriptive text that were generated by the LLM.

In Closing
Much like everything else on AIAR, this post will be a work-in-progress and is subject to update. The most compelling use-case I’ve found so far for AI is in automating the collection and formatting of references into my RSS workflow as this lets me do something that I might not otherwise make time for. I also find the article appraisal workflow compelling and plan to keep pushing on that to integrate it more into my regular workflow for keeping AIAR posts updated. I may also revisit use cases related to grounded synthesis and writing though I’m generally less optimistic about AI providing a real lift there. The work of framing and making connections in the literature, contextualizing findings, and thinking about what matters to an audience seem like they really need an expert eye, though perhaps LLMs can assist by offering a second opinion.
References
Fok R, Siu A and Weld DS (2025) Toward Living Narrative Reviews: An Empirical Study of the Processes and Challenges in Updating Survey Articles in Computing Research. Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems: 1–10.